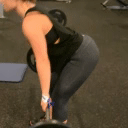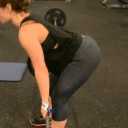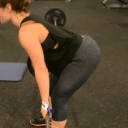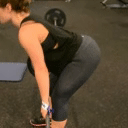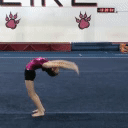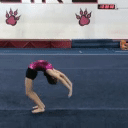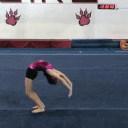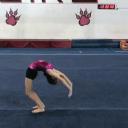Lijun Yu‡†, Yong Cheng†, Kihyuk Sohn†, José Lezama†, Han Zhang†, Huiwen Chang†, Alexander G. Hauptmann‡, Ming-Hsuan Yang†, Yuan Hao†, Irfan Essa†+, Lu Jiang† ‡Carnegie Mellon University, †Google Research, +Georgia Institute of Technology CVPR 2023 (Highlight)
We introduce MAGVIT to tackle various video synthesis tasks with a single model, where we demonstrate its quality, efficiency, and flexibility.
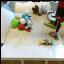
We compare different decoding methods to show the quality and efficiency of MAGVIT COMMIT decoding. We train a base transformer model with the same 3D-VQ tokenizer for each method.
Condition frames
Real videos
MAGVIT COMMIT decoding 12 steps (ours)
Autoregressive decoding 1024 steps
MaskGIT (Chang et al. 2022) MTM decoding 12 steps
Comparaing VQ Tokenizers on UCF-101
We compare different VQ tokenizers to demonstrate the superior reconstruction quality of MAGVIT 3D-VQ. These models are only trained on 9.5K training videos of the small UCF-101 dataset. See Perceptual Compression for large real-world examples of MAGVIT 3D-VQ.